Kristoffer Nielbo & Ryan Nichols
High performance computing and the massive increase of data available in digital databases have revolutionized several sciences. The Humanities and the Arts are beginning to feel the effects of this revolution, which has given new life to methods and research practice in fields like archaeology, linguistics, and literary studies (Cooper & Green 2015; Weikum et al. 2012; Jockers 2013). Not only this, but in some cases new research programs have emerged, including streams of the digital humanities (Arnold & Tilton 2015; Schreibman et al 2008). Although some areas of the humanities have adopted high performance computing in their research methods, many humanities scholars, including most of those in history and history of religion, have stuck to the traditional method of detailed descriptions and close readings of texts in order to extract patterns and formulate theories. Their trusted method, however, could be supplemented by digital databases.
The disciplines of religion and history deny themselves the benefits of new data-intensive techniques that helpful for exploring the human mind through historical evidence. Consider data mining, an interdisciplinary research field combining high performance computing and search in the quest to find meaningful patterns in data (Witten, Frank & Hall 2011). Data mining offers a range of techniques for modeling and testing claims about past minds. The application of data mining to textual data, or text mining, is especially relevant for historical texts in which explicit and implicit cognition is reflected in language use (Slingerland & Chaduk 2011). While archaeology has an established tradition of applying data mining techniques to material cultural artifacts, historical research and literary studies can develop similar tools for applying text mining to written sources. Without these tools, textual research is not fully able to mine cultural traditions that have passed on information through writing. This series of articles will serve as an guide to the techniques and methods of text mining.
First, we need to draw a distinction between structured and unstructured data. Structured data defines fixed fields for the stored data. For example, if we are studying novels, then our structured data will include categories like author name, location (country), and publication date. Let’s say we take an interest in 19th century novels written by women. Our items for Uncle Tom’s Cabin would be Harriet Beecher Stowe, United States, and 1852, while Middlemarch would include George Eliot, United Kingdom, and 1874. From the perspective of data mining, structured data are easy to store, query and analyze with a computer. Consider how easy it is to find items in cells in a spreadsheet by searching down a column or across a row. For these reasons, many historical databases use structured data, for example, the Database of Religious History.
Data in natural languages, such as primary literary sources from history, lack such fixed, computer-readable fields. This implies these are unstructured data. One must take considerable time to preprocess unstructured data with fixed fields so that they can be queried, quantified, and analyzed with data mining techniques. Full text databases primarily contain unstructured data, such as the Chinese Text Project or the Internet Sacred Text Archive. Luckily, text mining allows us to perform data mining techniques for modeling unstructured data. The remainder of this article exclusively concerns such techniques.
The qualitative humanist could argue that natural language is a type of data that does not follow mathematical laws. This, however, is incorrect (Banchs 2013). For instance, words often appear in bursts: when one word occurs in a text, it is likely to occur again in relative close proximity (Katz 1996). For any given text data set, according to Zipf’s law, a word’s frequency is inversely proportional to its rank (figure 1c) (Zipf 1935). This means that the most frequent word will be twice as frequent as the second most frequent word, three times as frequent as the third most frequent word, and so forth. This affects several relationships within the dataset, including those between vocabulary size, the number of unique word types, and the number of words total. In accordance with Heaps’ law, the vocabulary size will initially increase as more texts are added, but this increase will eventually taper off as more texts are added to the dataset (figure 1d) (Heaps 1978). The text analyst or mixed-methods humanist does well to argue that language is structured in a way that follows such statistical rules, and that historical research can use these rules in analyzing sources in order to make judicious inferences about writers’ mental states. However, text mining techniques can apply these rules in a more explicit and systematic manner to collections of texts larger than any human researcher could ever read in a lifetime.
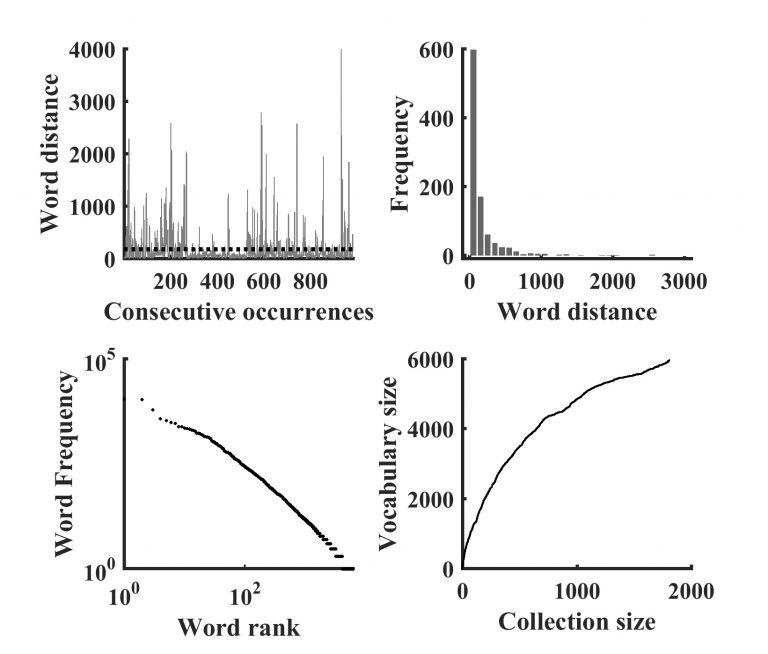
Figure 1: Fundamental properties of natural language (clockwise from upper left corner): a-b) Word burstiness. a) A time series showing the word distance between consecutive occurrences (proximity) of ‘Jesus’ in the KJV New Testament of the Bible (NT). The average distance separating two occurrences of ‘Jesus’ is 184 words (dotted line). b) The distribution of word distances shows that more than half of the distances are below 75 words or less than five sentences. c) Zipf’s Law. Word frequency rank (descending order) plotted against word frequency for NT in logarithmic space. d) Heaps’ law. Number of unique words (types) in NT plotted as a function of total words (tokens) in the collection of NT books (i.e., NT type.-token relation).
Text mining is a heterogeneous field that spans many different research areas, including Natural Language Processing, Information Retrieval, Web Mining, and Machine Learning (Miner 2012). The various applications of text mining have focused on text selection and cleaning on the one hand, and quantitative modeling and evaluation on the other (figure 2). This common methodology underlies several industrial standards for mapping data mining workflows. These standards include Knowledge Discovery in Databases, Sample-Explore-Modify-Model-Assess, and Cross-Industry Standard Process for Data Mining (Azevedo 2008; Fayyad, Piatetsky-Shapire & Smyth 1996). Although the application of industrial standards might seem out of place in the analysis of historical and literary texts, it is our firm belief that they can provide important new tools for Humanities research, and serve as helpful supplements, and even correctives, to traditional qualitative analysis. Moreover, the close connection between qualitative and quantitative components of a research project becomes clear when one considers how important cultural and linguistic domain expertise is for valid selection, interpretation, and evaluation of a text’s content.
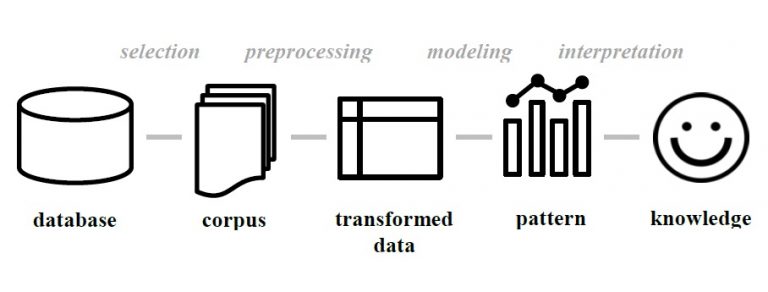
Figure 2: Common Methodology. Illustration of the different elements and steps of a text mining workflow.
In the next article, we will discuss how one might select a database for study.
Arnold, Taylor, and Lauren Tilton. 2015. Humanities Data in R: Exploring Networks, Geospatial Data,Images, and Text. 1st ed. 2015 edition. New York, NY: Springer.
Azevedo, Ana Isabel Rojão Lourenço. 2008. DzKDD, SEMMA and CRISP-DM: A Parallel Overview.dz (Jan 15, 2015) http://recipp.ipp.pt/handle/10400.22/136.
Banchs, Rafael E. 2013. Text Mining with MATLAB. 2013 edition. Springer.
Cooper, Anwen, and Chris Green. 2015. DzEmbracing the Complexities of ǮBig Dataǯ in Archaeology: The Case of the English Landscape and Identities Project.dzJournal of Archaeological Method and Theory, February.
Fayyad, Usama, Gregory Piatetsky-Shapiro, and Padhraic Smyth. 1996. DzFrom Data Mining to Knowledge Discovery in Databases.dz AI Magazine 17 (3): 37.
Jockers, Matthew L. 2013. Macroanalysis: Digital Methods and Literary History. 1st Edition edition. Urbana: University of Illinois Press.
Katz, Slava M. 1996. DzDistribution of Content Words and Phrases in Text and Language Modelling.dz Natural Language Engineering 2 (01): 15–59.
Miner, Gary. 2012. Practical Text Mining and Statistical Analysis for Non- Structured Text Data Applications. Waltham, MA: Academic Press.
Schreibman, Susan, Ray Siemens, and John Unsworth. 2008. DzThe Digital Humanities and Humanities Computing.dz In A Companion to Digital Humanities, by Susan Schreibman, Ray Siemens, and John Unsworth. Oxford: Blackwell.
Slingerland, Edward, and Maciej Chudek. 2011. DzThe Prevalence of Mind- Body Dualism in Early China.dz Cognitive Science 35 (5): 997–1007.
Weikum, Gerhard, Johannes Hoffart, Ndapandula Nakashole, Marc Spaniol, Fabian M. Suchanek, and Mohamed Amir Yosef. 2012. DzBig Data Methods for Computational Linguistics.dz IEEE Data Eng. Bull. 35 (3): 46–64.
Witten, Ian H., Eibe Frank, and Mark A. Hall. 2011. Data Mining: Practical Machine Learning Tools and Techniques, Third Edition. 3 edition. Burlington, MA: Morgan Kaufmann.
Zipf, George K. 1935. The Psycho-Biology of Language;: An Introduction to Dynamic Philology. 1st edition. M.I.T. Press.