Kristoffer Nielbo & Ryan Nichols
The real benefit of data intensive methods for research is their capacity to handle thousands and even millions of documents. While word counts and association mining provide an elevated perspective on a collection of documents, techniques for modeling relations between documents in large-scale databases present a bird’s-eye view (Moretti 2013). Sometimes collections of documents can be so large as to be unreadable in a lifetime. This is where algorithms for grouping and categorizing data come in. They support a researcher’s discovery of document similarities and relate these similarities to available metadata.
The field of Machine Learning is the primary source of such algorithms. The sheer volume of digital data, and the velocity with which they accumulate, result in a growing need for intelligent algorithms that can learn from data. Machine Learning is experiencing a popularity explosion[1] as a field, or subfield, of computer science that develops algorithms for pattern recognition and statistical learning (Bishop 2008; Hastie, Tibshirani & Friedman 2009). From these sources come many advanced techniques for text mining (Baharudin, Lee & Khan 2010). In this section, we will cover basic solutions to two common tasks: document clustering and document classification. Both tasks are extremely relevant to historical research and represent two generic learning tasks in Machine Learning: unsupervised and supervised learning, respectively.
Document clustering
The basic task of a clustering algorithm is to group a collection of data into clusters useful for answering one’s research questions (Pan-Nang, Steinbach & Kumar 2005). Typically documents are clustered with semantic or stylistic features in mind (Manning, Raghavan & Schütze 2008). Document clustering requires the use of an unsupervised learning algorithm—that is, an algorithm that learns the underlying clusters of a data set without the use of preexisting class values that label this structure.
To illustrate document clustering, we can apply a clustering algorithm to the books of the New Testament (NT) research corpus. Traditionally the books of NT are grouped using the following class values: Historical books, Pauline Epistles, and Non-Pauline Epistles. If these class values are withheld from the learning task through unsupervised learning, it is interesting to see what groups the algorithm will find. In this case, we have to apply a document clustering algorithm to the distance matrix of the documents (columns) in the document-term matrix (figure 1).
Document clustering distinguishes between two types of clustering: flat and hierarchical clustering (Manning, Raghavan & Schütze 2008). In flat clustering, the algorithm divides the documents into a set of non-overlapping clusters that are not interrelated in any way, creating a flat structure. In contrast, hierarchical clustering creates a group of clusters that are made to be interrelated in a hierarchical nested tree structure. Applying a flat clustering algorithm to the NT books gives us a model with three clusters that are roughly similar to the traditional class values (figure 1a). The model includes some Non-Pauline (James, 1Peter, Hebrews and James) in the Pauline group, and the Book of Revelation is included among the Historical Books. The case of Revelation is interesting because the model seems to find narrative features similar to the Historical Books. A model based on a hierarchical clustering algorithm is similar, but it creates four general clusters (figure 1b). The nested structure shows that Revelation, although it is included in the Historical cluster, is dissimilar from the remaining members. As a result, it branches away at the highest level. The model identifies the unity of the Synoptic Gospels by nesting them close together in the Historical cluster.
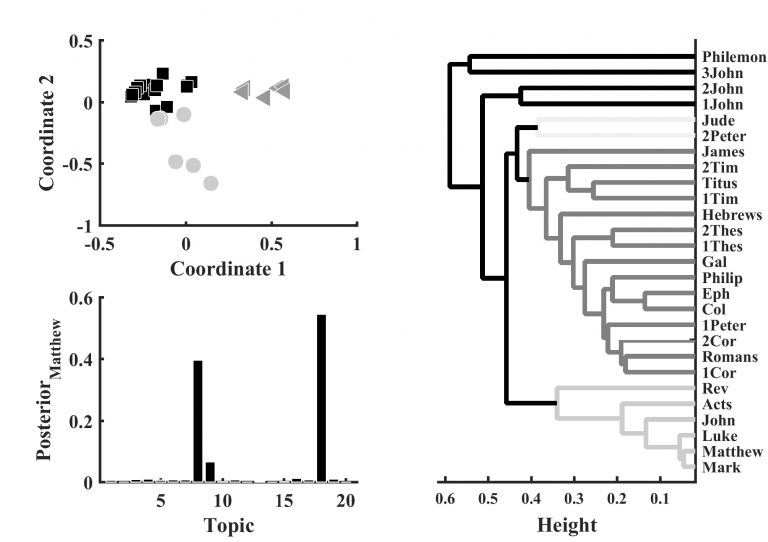
Figure 1: Document clustering (clockwise from upper left corner): a) Three cluster in the NT identified with a flat and hard clustering algorithm. The clusters roughly align with the Historical books (triangles), Pauline Epistles (squares), and Non-Pauline Epistles (circles). c) A dendrogram based on a hierarchical hard clustering algorithm that identifies four clusters of books within the NT (light grey to black). The more similar two documents are the closer their branches are. c) Topic distribution for the Gospel of Matthew in topic model of NT. Algorithms used for topic modelling (e.g., VEM) perform soft clustering.
Another useful distinction in document clustering is hard versus soft clustering (Manning, Raghavan & Schütze 2008). In hard clustering, documents are assigned to one cluster only. Soft clustering, on the other hand, assigns documents to more than one cluster by calculating a document’s distribution over all clusters. The flat clustering algorithm applied to the NT books is hard, that is, each book is only a member of one cluster. The hierarchical cluster algorithm allows for overlapping clusters (e.g., Synaptic cluster within the Historical cluster), but the model is not soft, because a document is not treated as a distribution over all clusters. For model interpretation, we cut the number of clusters to four to define exclusive cluster membership.
True soft clustering brings us to topic models, which have become increasingly popular in the computationally-informed Humanities. Topic models are a set of probabilistic models that perform soft clustering of documents (Blei, Ng & Jordan 2003; Miner et al., 2009). Algorithms for topic modeling are generative, that is, they try to infer the hidden topics for that collection of documents (Blei 2012). A topic model can be used to cluster both words and documents. A topic is a cluster of co-occurring words, and a document is a cluster of topics. Because topic modeling is a soft clustering technique, it captures the intuition in discourse analysis that a document is a mixture of several topics.
To illustrate topic modeling, we ran a (variational expectation-maximization) algorithm on the books of NT in order to estimate 20 topics in a Latent-Dirichlet Allocation model, which is a simple type of topic model (Blei, Ng & Jordan 2003). For the sake of simplicity, this illustration focuses on the Book of Matthew (figure 1c). Matthew is a discrete probability distribution over all topics, but most topics are only marginally present. The posterior probabilities of topics 8, 9 and 18 are, however, considerably different from zero. Common to these three topics are keywords such as ‘Jesus’, ‘say/said’, and ‘man’. In contrast, topics 11 and 15 dominate Revelation, which are characterized by ‘God’, ‘angel’, ‘beast’, ‘earth’ and ‘heaven’. Comparing the topic spaces of the two documents shows that they do not cluster in terms of topics. Because the model is sensitive to when words occur together, it tracks Matthew’s historical content and Revelation’s apocalyptic content. In contrast, both Mark and Luke overlap considerably with Matthew in topic 8 and 9. Further analysis actually revealed that topic 18 tracks features that are unique to Matthew, topic 9 tracks features that Matthew shares with Mark, and topic 8 consists of features common to Matthew, Mark, and Luke.

Topic models have received extensive use recently in the digital humanities. Perhaps the most well-known use of topic models in this community is Matthew Jockers’ book Macroanalysis. This is not only an excellent non-technical introduction to analytically-minded digital humanities but an elegant display of the use of exploring topic models and their versatility to answer—and prompt—research questions. As of now we do not know of plug-and-play topic modeling programs or web-based services. In other words, at least for the time being, one must work within software environments like MALLET or MATLAB or code (or run others’ scripts) in R or Python. However, we expect that in the very near future developers will have available web-based topic modeling services.
[1] In 2015 ML peaked in Gartner’s Hype Cycle for Emerging Technologies, thereby replacing Big Data from the previous year: http://www.gartner.com/newsroom/id/3114217 (January 12, 2016).